Rene Descartes’in meşhur sözüdür; “Cogito, ergo sum.” Ya da bizim bildiğimiz şekliyle “Düşünüyorum, öyleyse varım.” Bu sözle Descartes, bir varlığın gerçekliğini ya da var oluşunu düşünce üzerinden tanımlıyor. Yani, düşünen bir şey vardır.
Daha önceki yazılarda da belirttiğim gibi, özellikle Kasım 2022’de "herkesin" erişimine açık bir şekilde sunulan ve Generative Pretrained Transformer (GPT) kullanılarak eğitilen büyük dil modeli ChatGPT’den itibaren yapay zekâ alanındaki ilerlemeler inanılmaz bir seviyeye ulaşmış durumda. Öyle ki neredeyse iki haftada bir yeni bir dil modelinden bahsetmek zorunda kalıyorum, aslında bundan bir miktar rahatsızım. Fakat LLM alanındaki “kartel” yarışı öyle bir hal aldı ki, bu alana ilgi duyan herkesin dikkati ister istemez buraya yöneliyor.
ChatGPT’nin yaratıcısı OpenAI firması, geçtiğimiz aylarda 4o ve sesli asistan özellikleri içeren bir model tanıtmış, ancak buradan istenilen geri dönüş sağlanamamıştı. Özellikle Meta’nın açık kaynak olarak duyurduğu Llama 3.1 modelinin bu modele kıyasla avantajlara sahip olduğunu geçtiğimiz haftalarda bahsetmiştim.

Ancak, dediğim gibi burada “şimdilik” ne zaman duracağını kestiremediğimiz bir yarış var ve bu nedenle OpenAI durmadı ve bu hafta başında yeni dil modelleri o1-preview ve o1-miniyi tanıttılar.
Ama önce ufak bir hatırlatmayla hafızaları tazeyelim.
Büyük dil modelleri, geniş veri kümeleri üzerinde eğitilerek dilin kurallarını ve kalıplarını öğrenen ve bu bilgiyi çeşitli görevlerde kullanan yapay zekâ modelleridir. Bu tanımdaki "büyük" terimi, hem modelin boyutunu hem de eğitildiği veri kümesinin büyüklüğünü ifade eder. Bu modeller, metin üretme, metin tahmini, çeviri ve soru-cevap sistemleri gibi çeşitli görevlerde kullanılır.
OpenAI'nin yeni modelleri o1-preview ve o1-mini, tıpkı diğer büyük dil modelleri gibi geniş veri kümeleri üzerinde eğitilerek dilin kurallarını ve kalıplarını öğrenen yapay zekâ modelleri. Ancak bu modelleri önceki versiyonlardan ayıran önemli bir özellik var: Düşünce zinciri (chain-of-thought reasoning) adı verilen bir yöntem kullanmaları. Bu yöntem sayesinde modeller, doğrudan bir cevap vermek yerine, mantıksal adımları takip ederek ve farklı stratejiler deneyerek sonuca ulaşıyorlar. Bunu sağlayan ise modellerin pekiştirmeli öğrenme (reinforcement learning) ile eğitilmeleri. Modeller, belirli görevleri yerine getirirken ödül veya ceza alarak daha iyi kararlar almaya teşvik ediliyorlar. Bu, modellerin karmaşık problemleri daha iyi anlamalarını, daha tutarlı yanıtlar üretmelerini ve nasıl bir sonuca vardıklarını daha şeffaf bir şekilde göstermelerini sağlıyor.
o1-preview modeli, özellikle matematik, kodlama ve bilimsel problemler gibi karmaşık alanlarda üstün performans sergiliyor. Örneğin, Uluslararası Matematik Olimpiyatı'nın seçme sınavında GPT-4o modeli soruların sadece yüzde 13'ünü doğru yanıtlarken, o1-preview modeli yüzde 83'lük bir başarı oranı yakalamış. Benzer şekilde, programlama yarışmaları olan Codeforces'ta bu yeni model, katılımcıların yüzde 89'undan daha iyi performans göstermiş. Ayrıca, fizik, kimya ve biyoloji gibi alanlarda doktora seviyesindeki sorularda insan uzmanlara yakın veya bazen daha iyi sonuçlar elde etmiş. Bu, yapay zekâ modellerinin artık sadece dil üretimiyle sınırlı kalmayıp, derinlemesine düşünme ve problem çözme yeteneklerine de sahip olmaya başladığını gösteriyor.
o1-mini modeli ise daha küçük ve hızlı bir seçenek olarak karşımıza çıkıyor. Kodlama konusunda etkili olan bu model, daha düşük maliyetli olmasıyla da dikkat çekiyor. Bu, geliştiriciler ve küçük işletmeler için yapay zekâ uygulamalarını daha erişilebilir hale getirebilir.
Bu modelleri farklı kılan sadece belirli alanlardaki yüksek performansları değil. Aynı zamanda multimodal yeteneklere de sahipler, yani sadece metin değil, görüntü, video ve ses gibi farklı veri türlerini de işleyebiliyorlar. Bu, modellerin daha geniş bir bağlamı anlamasına ve daha zengin yanıtlar üretmesine olanak tanıyor.
Ancak bu modellerin vaat ettiği derin düşünme süreci, bazı sınırlamaları da yanında getiriyor. Modellerin derinlemesine düşünme süreçleri, geri dönüş hızlarını önemli ölçüde yavaşlatıyor. Özellikle o1-preview modelinin bazı durumlarda yanıt vermesi 10-20 saniyeyi bulabiliyor veya hiç yanıt vermeyebiliyor. Bu yavaşlık, kullanıcı deneyimini olumsuz etkileyebilir ve pratik uygulamalarda hız ve verimlilik sorunlarına yol açabilir. Ayrıca, bu modellerin kullanım maliyetleri de önceki modellere göre oldukça yüksek. API üzerinden o1-preview modelini kullanmanın maliyeti, GPT-4o modeline kıyasla dört kat daha fazla.
Modellerin “düşünce zinciri” nedeniyle yoğun hesaplama gücü gerektirmesi, enerji tüketimi ve sürdürülebilirlik açısından da soru işaretleri doğuruyor. Yapay zekânın çevresel etkileri, giderek daha fazla tartışılan bir konu haline geliyor ve bu modellerin yaygınlaşması bu tartışmaları daha da alevlendirebilir.
Bunun yanında, modellerin güvenilirliği ve etik kullanımı konusunda da bazı endişeler mevcut. Her ne kadar o1 modelleri halüsinasyon oranını azaltmış olsa da, tamamen ortadan kaldırılmış değil. Modellerin bazen gerçeğe dayanmayan veya hatalı bilgiler üretme olasılığı hâlâ var. Ayrıca, modellerin karar alma süreçlerinin karmaşıklaşması, şeffaflık ve hesap verebilirlik konularında yeni zorluklar ortaya çıkarıyor.
Ayrıca o1 modelleri şu an için web'de gezinme, dosya ve resim yükleme gibi özelliklere sahip değiller. Bu da, modelin pratik kullanım alanlarını sınırlıyor. Dil anlama ve yaratıcı yazma gibi görevlerde de GPT-4o modelinin gerisinde kalabiliyorlar. Bu da farklı ihtiyaçlar için farklı modellerin daha uygun olabileceğini gösteriyor.
O1 modelleri “düşünme” yeteneğine dair ilk emareleriyle yeni bir kapıyı araladı şüphesiz. Ancak bu alanın büyük bir kapital yarışı haline gelmesi, gelecek adına düşünmemiz gereken başta çevre ve etik olmak üzere pek çok soru ve endişeyi de akıllara getiriyor. Yapay zekânın nereye doğru evrileceği ve bu yolculukta insanlığın rolünün ne olacağı, hepimizin ortak sorumluluğu ve merakı olmalı.
Düşünmek için bir fırsat.
|
Ozancan Özdemir kimdir?
Ozancan Özdemir, lisans ve yüksek lisans derecelerini ODTÜ İstatistik Bölümü'nden aldı. Yüksek lisans döneminde aynı zamanda Anadolu Üniversitesi yerel yönetimler bölümünden mezun oldu.
Bir süre ODTÜ İstatistik Bölümü'nde araştırma görevlisi olarak çalışan Özdemir, şu günlerde Groningen Üniversitesi Bernoulli Enstitüsü'nde finans ve yapay zekâ alanındaki doktora çalışmalarını sürdürüyor.
Pandemi döneminde bir grup öğrenciyle birlikte gönüllü bir oluşum olan VeriPie adlı güncel veri gazetesini kurdu.
Araştırma alanları yapay öğrenme ve derin öğrenme uygulamaları, zaman serisi analizi ve veri görselleştirme olan Ozancan Özdemir, ayrıca yerel yönetimler ve veriye dayalı politika geliştirme konularında da çeşitli platformlarda yazılar yazmaktadır.
|

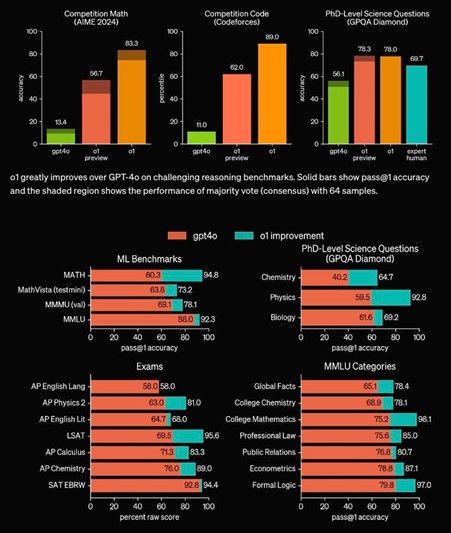 Figure 1: o1 Model Performansları
Figure 1: o1 Model Performansları 