












Google’nın derin öğrenme alanında önemli, hatta çok önemli, bir gelişme olan attention (dikkat) mekanizmasını yayınladığı makalenin başlığıydı Attention is All You Need (Tüm İhtiyacınız Dikkat.) Kesinlikle doğru bir önermeydi bu, öyle ki bu mekanizmanın tanıtılmasının hemen arkasından çok ciddi bir ilerleme yaşandı derin öğrenme dünyasında. Bugün çoğu insanın hayatının bir parçası olan Large Language Models (Büyük Dil Modelleri) de bu mekanizmayı kullanan modellerden.
Attention kadar önemli, hatta bence daha önemli bir ihtiyacımız daha var aslında. Türkçe adı veri, ama artık dillerimize pelesenk olan bir diğer adıyla data. Başta dil modelleri olmak üzere tüm derin ve yapay öğrenme modelleri eğitilmek için veriye ihtiyaç duyar, yani siz ne kadar ileri derecede bir model mekanizması da geliştirmiş olsanız yeterli miktarda veriniz yoksa modeli eğitemez, istenilen başarıya ulaşamazsınız.
Büyük dil modelleri seçili derlemelerden ya da internetten elde edilen çok çok büyük boyutta, gerçekten çok büyük, metin verilerinin güdümsüz öğrenme tekniği ile eğitimine dayanır. Üstelik bu modeller nöral ölçeklendirme kullanır ki bu da dil modellerinin performansını verimli bir şekilde iyileştirmek için eğitim veri kümelerinin boyutunu artırmanın çok önemli olduğu anlamına gelir. Kısacası ne kadar çok metin o kadar çok başarı. (Genellikle…)
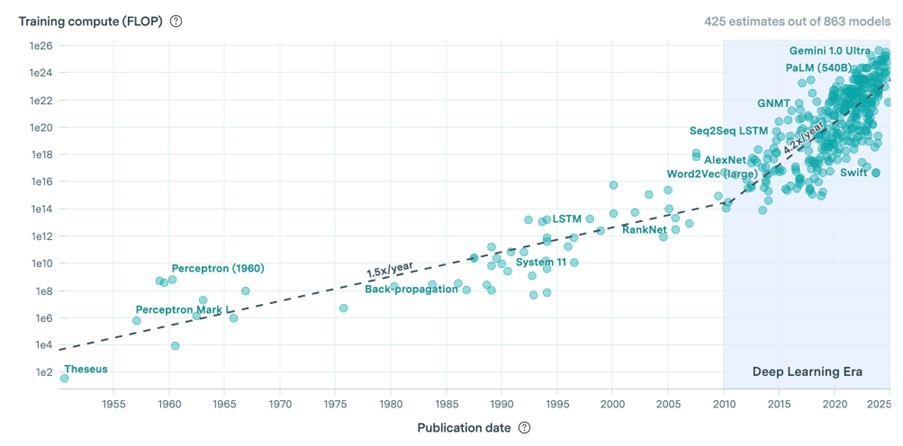 Figür 1: Bilinen yapay ve derin öğrenme modelleri ile onların eğitimi için kullanılan veri miktarı (Epoch)
Figür 1: Bilinen yapay ve derin öğrenme modelleri ile onların eğitimi için kullanılan veri miktarı (Epoch)
Bu hafta içerisinde Euronews’te yayınlanan Çağla Üren imzalı haberde, OpenAI’ın yeni dil modelinin başarısının istenilen seviyenin altında kaldığı ve bunun nedeni olarak da modelin eğitiminde kullanılacak yeterli miktarda kaliteli eğitim verisinin olmayışı gösteriliyordu. Bu gelişmenin yaşanması kaçınılmazdı, çünkü dil modelleri artık bir tür zenginler yarışına dönmüş durumda ve tek amaç daha iyi olan modeli üretip paraya dönüştürmek. Ancak bu hızlı ve belki de “vahşi” ilerlerleme şu an LLM dünyası adım adım bir “veri krizine” doğru sürüklüyor olabilir.
Haziran ayında yapılan bir çalışma yapılan bir çalışma mevcut insan üretimi metin verisinin büyük dil modellerinin eğitimi üzerinde daha ne kadar sürdürülebilir olduğunu araştırmış. Çalışmada geliştirilen modele göre internetteki metin verilerinin toplam stoğu, kabaca 400 trilyon token, büyük dil modellerinin eğitimi sırasında metinleri işlemeye uygun birimlere ayırma sürecinde kullanılan, genellikle bir kelime, kelime parçası veya karakterden oluşan temel veri birimi, olarak tahmin ediliyor. Öte yandan bir dil modeli eğitmek için kullanılan eğitim verilerinin boyutu da her geçen yıl 2.4 kat artıyor. Bu hızlı büyüme, mevcut eğilimler devam ederse, LLM'lerin 2026 ile 2032 yılları arasında, hatta aşırı eğitim verilmesi durumunda daha da erken bir tarihte insan üretimi veri stoğunu tüketeceğini öngörüyor ki bu da mevcut hızlı gelişmelerin yavaşlaması ve belki de dark era (karanlık çağ) başlamasına neden bile olabilir. Yani bu veri krizinin derin bir şekilde yakın gelecekte karşımıza çıkması muhtemel bir senaryo.
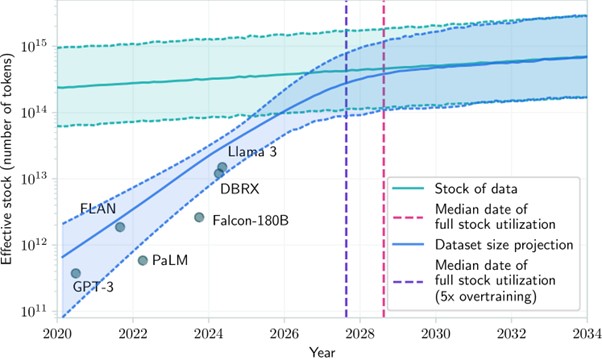
Figür 2 : Kayda değer LLM'leri eğitmek için kullanılan insan tarafından oluşturulan kamuya açık metin ve veri kümesi boyutlarının etkin stoğunun projeksiyonu (Villalobos vd, 2024)
Peki ne yapılabilir? Elbette ki bu veri kıtlığı yeni gündem olan bir konu değildi ve daha önceden tahmin ediliyordu. Dolayısıyla zaten birtakım stratejiler geliştirilmişti ve kullanılmaya başlanmıştı. Çalışma bu önerilere de yer veriyor.
Mevcut ve gelecekte daha da derinleşmesi ön görülen bu veri kıtlığını aşmak için geliştirilen önerilerden ilki sentetik veri üretimi. Bu yöntem büyük ölçekli veri üretimi için umut vaat etse de modelin veri çeşitliliğini kaybetme ve çıktılarının homojenleşmesi gibi sorunlar ortaya çıkabiliyor. Ayrıca, matematik ve programlama gibi doğrulanması kolay alanlarda başarılı olan bu yöntem, doğal dil gibi doğrulamanın daha zor olduğu alanlarda aynı başarıyı gösteremeyebilir.
Metin dışındaki veri türleriyle (ör. görüntü ve bilimsel veri tabanları) eğitim yapmayı öneren çok modlu öğrenme ve transfer öğrenimi bir diğer çözüm. Ancak bu yöntemlerin dil modellemesinde her zaman uygulanabilirliği belirsiz. Öte yandan, halka açık olmayan verilere (ör. sosyal medya veya mesajlaşma uygulamaları) yönelmek, veri miktarını artırabilir. Ancak bu yaklaşım, veri gizliliği ihlalleri ve yasal sorunlar yaratabileceği gibi, sosyal medya içeriklerinin düşük kalitesi ve verilerin farklı platformlara dağılmış olması gibi dezavantajlara sahip.
Son olarak, veri verimliliği teknikleri, yani daha az veriyle daha iyi performans sağlama metotları da öneriler arasında. Daha verimli algoritmalar ve eğitim teknikleri, mevcut verilerden daha fazla bilgi çıkarmamıza yardımcı olabilir. Ancak, bu tekniklerin veri darboğazını tamamen ortadan kaldırıp kaldıramayacağı belirsizliğini koruyor.
Görünen o ki, veri kıtlığına dair mevcut stratejiler var olsa da bu stratejilerin henüz tüm şüpheleri giderebilmiş olduğunu ve insan üretimi metin verisi kalitesinde çıktı sağlayacak yetkinliğe ulaştıklarını söylemek güç. Dolayısıyla, mevcut hızın bir süre daha aynı şekilde ilerleyeceği varsayımı altında, kapitaller arası vahşi yarışta yeni bir aşamaya giriş yapacağımızı öngörebiliriz. Gelecekte, üstelik kısa bir gelecekte, bu modellerin daha fazla veri toplamak için kolay ulaşılabilir hale geldiğini ve pek çok günlük kullanımımızdaki cihaz ve uygulamalara eklemlendiğini görebiliriz. Bir başka deyişle, sermaye için her birimiz olduğumuzdan da büyük bir veri ambarına dönüştürülebiliriz.
Ancak, bu durum büyük dil modeli teknolojisinin önündeki bariyerleri kaldırmaya yarayabilir olsa da, beraberinde pek çok kişisel veriye dayalı etik sorunu getirecektir. Örneğin, günlük yaşamımızda kullanılan cihazlar ve uygulamalardan bireylerin rızası olmadan veri toplamak, kullanıcı gizliliğini ciddi şekilde ihlal edebilir. Bu noktada, araştırmacıların ve teknoloji şirketlerinin şeffaflık ilkesi doğrultusunda, kullanıcıların açık rızasına dayalı veri toplama politikaları geliştirmesi bir zorunluluktur. Ayrıca, veri kaynaklarının birkaç büyük teknoloji şirketinin kontrolünde yoğunlaşması, veri monopollerini ve dijital eşitsizliği daha da derinleştirebilir. Bu, hem araştırmacılar hem de politika yapıcılar için adil erişim politikaları oluşturmayı zorunlu kılmaktadır. Son olarak, bu gelişmelerin yalnızca teknik ve ekonomik boyutlarına odaklanmak yerine, veri güvenliği, kullanıcı gizliliği ve toplumsal eşitlik gibi etik önceliklerin de teknoloji geliştirme süreçlerine entegre edilmesi, sürdürülebilir ve adil bir teknoloji ekosistemi yaratmak için vazgeçilmezdir.
Referanslar
Villalobos, P., Ho, A., Sevilla, J., Besiroglu, T., Heim, L., & Hobbhahn, M. (2022, October 26). Will we run out of data? Limits of LLM scaling based on human-generated data. arXiv.org. https://arxiv.org/abs/2211.04325
|
Ozancan Özdemir kimdir? Ozancan Özdemir, lisans ve yüksek lisans derecelerini ODTÜ İstatistik Bölümü'nden aldı. Yüksek lisans döneminde aynı zamanda Anadolu Üniversitesi yerel yönetimler bölümünden mezun oldu. Bir süre ODTÜ İstatistik Bölümü'nde araştırma görevlisi olarak çalışan Özdemir, şu günlerde Groningen Üniversitesi Bernoulli Enstitüsü'nde finans ve yapay zekâ alanındaki doktora çalışmalarını sürdürüyor. Pandemi döneminde bir grup öğrenciyle birlikte gönüllü bir oluşum olan VeriPie adlı güncel veri gazetesini kurdu. Araştırma alanları yapay öğrenme ve derin öğrenme uygulamaları, zaman serisi analizi ve veri görselleştirme olan Ozancan Özdemir, ayrıca yerel yönetimler ve veriye dayalı politika geliştirme konularında da çeşitli platformlarda yazılar yazmaktadır. |







