
20 Nisan 2020
Endüstri 4.0'ın başlamasını ve gelişmesini etkileyen en belirleyici faktörlerin başında Büyük Veri gelmektedir. Ancak büyük veri sadece verinin hacim olarak büyük olması ile ilgili bir kavram değildir.
Öyleyse nedir bu büyük veri?
Bu kavram, 2000'li yılların ortalarında, astronomi ve genom bilimi gibi bilimler ile uğraşan bilim insanları tarafından ortaya atıldı. Ancak, kavram artık insanın uğraş gösterdiği bütün alanlara taşınıyor.
Önce Büyük Veri'nin hangi sorulara cevap verdiğine bir göz atalım: "Büyük veri, neden değil, ne hakkındadır. Bir olayın nedenini her zaman bilmemiz gerekmez; aksine verinin kendi adına konuşmasına izin verebiliriz." [1]
Tanımdan da anlaşılacağı üzere, büyük verinin kendisi olaylarla ilgili yorum yapmaz; ancak büyük verinin içindeki bilgiler ile arasındaki ilişkisi algoritmik olarak kurulabilirse yorumu insanlar ve yapay zekâ yapabilir. Büyük veri kullanılarak olaylar hakkında iç görüde bulunabilir, bunların üzerinde de yeni değerler yaratabiliriz. Endüstri 4.0'ın itici gücü birbiriyle konuşarak planlama yapan, öğrenen makineler, robotlar değil, bunların yakıtı olan büyük verinin kendisidir. Büyük verinin olmadığı yerde bu makinelerin, robotların ve daha da önemlisi öğrenen makinelerin ve AI (yapay zekâ) kullanılması söz konusu olamaz.
Büyük veri konusunda yazan araştırmacılar ve bilim insanlarının büyük çoğunluğu kavramı 3V modeli ile açıklamaktadırlar. Bu 3V; Volume (Hacim), Variety (Çeşitlilik) ve Velocity (Sürat)'tir. Bu tanımlamaya, Türk araştırmacı/yazar Ogan Özdoğan bir "V" daha ilave ediyor; Value (Değer).[2]
Elimizdeki verilerden yeni değerler üretemiyorsak, sadece bilgisayar disklerinde depoluyorsak, bu veri tamamen çöptür; hem de çok pahalı bir çöp.
Büyük veri kavramını daha iyi anlayabilmemiz için sayısallaştırma (Digitalisation) ve verileştirme (Datafication) arasındaki farkı kavramamız gerekmektedir. Bu farkı örnek bir olayla açıklamaya çalışalım:
Google 2004 yılında elde edebilecekleri tüm kitapları tarayıp, okuyucuların hizmetine sunacağını ilan etti. Kütüphanelerle de işbirliği yaparak milyonlarca kitap, sayfa sayfa tarandı. Ancak bu tarama sonucunda elde edilen sayfalar birer dijital fotoğraftı. Okuyucuların bu kitaplar içinde bir arama yapması mümkün değildi. Aradığı bilgiye ulaşmak için tüm kitabı okuması gerekiyordu.
Şirket sayfa görseli şeklindeki sayısallaşma uygulamasının yeterince faydalı olmadığını fark edince verileştirmeye geçme kararı aldı. Taradıkları tüm kitap sayfalarını alıp, üzerindeki harfleri, kelimeleri, cümleleri ve paragrafları optik karakter tanıma (OCR- Optical Character Recognition) yazılımı kullanarak yazı metnine çevirdi. Sonuç, sayfanın sayısallaştırılmış resminden çok verileştirilmiş metindi.
Artık sayfanın üzerindeki bilgi, sadece insan okurlar tarafından kullanılabilir olmakla kalmayıp, bilgisayarlar tarafından işlenebilir ve algoritmalar tarafından analiz edilebilirdi. Verileştirme, metni endekslenebilir ve dolayısıyla aranabilir hale getirdi. Buna ek olarak, sonsuz metin analizi akışına izin verdi.[3]
Büyük Veri'yi doğru anlayabilmek için 'Veri Ölçü Birimi'ni de doğru kavrayabilmek gerekiyor. Nasıl ki "gram" (gr) ağırlık ölçü birimi olarak kabul diliyorsa, verinin de temel ölçü birimi "bit" (veya "b") olarak tanımlanır. Verinin temel ölçü birimi olan "bit" en temelde verinin var veya yok (1 veya 0 ile gösterilir) olduğu bilgisini iletir. 8 adet bit'in bir araya gelmesi ile oluşturulan veri grubu da "Byte" (veya "B") olarak tanımlanır. Gramın bin katı karşılığı 1 kg olarak gösterildiğinde "Kilo" üç sıfır koymak anlamına geliyorsa, 8 bit, yani 2 Byte'ın yaklaşık 1000 katıda (aslında 1024 katı) 1KB ile gösteriliyor. Yaklaşık 1 milyon katı da 1MB olarak gösteriliyor. Mobil telefon alırken, internet kullanırken, dijital bir dosya postalarken veri ölçü birimlerini ve katlarını sıkça kullanıyoruz.
Ancak büyük veri ile birlikte yeni ölçü birimleri de oluştu ve günlük yaşamımıza da girdi. Büyük verinin hacmini anlayabilmemiz için aşağıdaki ölçü birimlerine bir göz atalım.
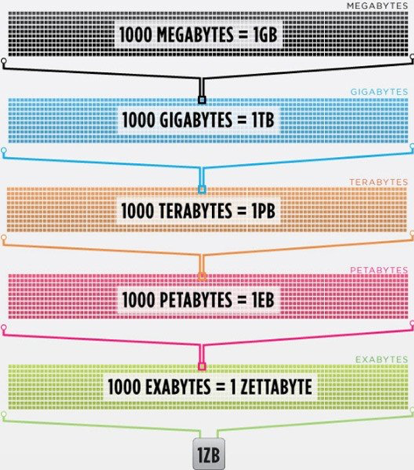
Şimdilik kullanılan en uç birim Zettabyte'dır. 2015 yılında küresel olarak 7.9 zettabayt olan veri hacminin, 2020 yılında 35 zettabayt olacağı düşünülmektedir. Bir zettabyte'ın 35 trilyon gigabyte eşit olduğu göz önüne alınırsa büyük verinin boyutu hakkında biraz fikir sahibi olabiliriz.
Büyük veriyi daha iyi anlayabilmemiz için nasıl büyüyüp geliştiğine bir göz atmakta yarar var.
Endüstrileşmenin geçiş dönemlerine baktığımızda, önceleri üretimde, iletişimde ve ulaşımda makinalar kullanılmış daha sonra da bilgisayar kullanımı hızla artmıştır.
Bilgisayarlar ile makinaların kontrol edilip, otomatize edilmesi ile birlikte, üretimde ana eleman olarak robotlar kullanılmaya başlanmıştır. Bu durum vasıfsız işçiye olan ihtiyacın azaltılmasını ve son aşamada karmaşık ve yeti gerektiren işlerin de makineler (daha da önemlisi öğrenebilen makineler/bilgisayarlar) tarafından yapılabilmesini sağlayacaktır.
Böylece, bilgi birikiminin makineler tarafından kullanılacağı yeni bir döneme girmiş olduk. Bu dönemde, makineler zaten bilgisayar ile kontrol edildiği, finans, iş dünyası, iletişim ve ulaşımda bilgisayarlar son derece yaygın olarak kullanıldığı ve tabii nerede ise herkesin taşıdığı akıllı telefonların da bir bilgisayar olduğu gerçeğini göz önüne aldığımızda, dünyamızda ne kadar çok bilgi biriktiğini hayal edebilirsiniz.
2020 itibariyle gezegendeki her insan için her saniye yaklaşık 1,7 megabayt yeni verinin yaratılacağı tahmin ediliyor. Bu veri sadece e-posta, WhatsApp, Facebook, Twitter gibi sosyal medya aracılığı ile her saniye birbirimize gönderdiğimiz on milyonlarca mesajdan ve e-postadan gelmiyor
Ayrıca her yıl çektiğimiz bir trilyon dijital fotoğraftan ve gittikçe artan miktarda video verisinden de kaynaklanıyor. Şu anda her dakika Youtube'a 300 saat yeni video yükleniyor ve Facebook'ta neredeyse üç milyon video paylaşılıyor.
Bunların yanında artık dört bir yanımızı sarmış olan tüm o sensörlerden alınan veriler de var. Yeni akıllı telefonlar nerede olduğumuzu (GPS), hareket etme hızımızı (ivmeölçer), etrafımızdaki havanın nasıl olduğunu (barometre), dokunmatik ekrana basmak için ne kadar güç uyguladığımızı (dokunma sensörü), anlık sağlık durumuzu ölçen ve benzeri daha pek çoğunu söyleyen sensörlere sahipler.
2020 itibariyle dünyada altı milyardan fazla akıllı telefona sahip olacağız ve bunların hepsi veri toplayan sensörlerle dolu olacak. Ama sadece telefonlarımız akıllı hale gelmiyor, artık akıllı televizyonlarımız, akıllı saatlerimiz, akıllı sayaçlarımız, akıllı su ısıtıcılarımız, buzdolaplarımız, tenis raketlerimiz ve hatta akıllı ampullerimiz var. Aslında 2020 itibariyle 50 milyardan fazla cihaz internete bağlı olacak. Yani kısaca "Her Şey" internete bağlanacak ve dolayısı ile internet nesnelerin interneti ("Internet of Things") olacak.
"Tüm bunlar, dünyadaki veri miktarının ve çeşitliliğinin (sensör verilerinden, metin ve video verilerine kadar) hayal edilemeyecek seviyelerde büyüyeceği anlamına geliyor."[4]
Veri hacminin artmasındaki en büyük sebep, bilinenin aksine insanlar değildir; makineler, akıllı okuyucular, uydular, cep telefonları, bilgisayarlar, tablet bilgisayarlar gibi daha sayılabilecek pek çok cihazdan yapısal olmayan veri tipinde veriler üretilmektedir.

Nesnelerin İnterneti (Internet of Things) vasıtasıyla toplanan veriler büyük verinin önemli bir kısmını oluşturmaktadır. Nesnelerin İnterneti, insanların doğrudan kullanımı dışında, makinelerin ürettiği veriyi ileten araçtır. "Nesnelerin interneti, bünyesinde gömülü yazılım teknolojilerinin olduğu ve bu teknolojiyi diğer objelerle iletişim kurmak için kullanan bir fiziksel objeler ağıdır. Örnek olarak evinizde internete bağladığınız televizyonunuz ya da bir bulut bilişim sistemine bağlanarak gerçek zamanlı veri alabilen bir otomobil verilebilir."[5]
Bu konuya daha sonraki yazılarımda değineceğim. Şimdi Nesnelerin İnterneti vasıtasıyla oluşan veriyi bir kaç örnekle anlatayım:
Bir Boeing 737 motoru uçuş esnasında her 30 dakikada bir toplam 10 terabayt veri üretmektedir. Başka bir ifadeyle İstanbul'dan New York'a uçtuğunuz sürede sadece bu motor 220 terabayt veri üretecektir. Onlarca uçağı yönettiğiniz filonuz ve her saat farklı uçaklarla, farklı uçuşlar gerçekleştiren bir firmanız varsa, verinin üretim hızını siz düşünün.[6]
Ebay gibi alış veriş sitelerinin satışlarının artırabilmelerinin en önemli koşulu tüketicilerinin tercihlerini tahmin edebilmeleridir. Bu sayede size alış veriş esnasında ve sonrasında yeni ürünler tavsiye ederler.
Bunu gerçekleştirebilmenin bir yolu, "Dünkü aramalarda en çok listelenen ürünler hangileri olmuştu?" ve "Bunlardan hangisi sizin daha çok ilgini çeker?" sorusunun cevabını bulmaktan geçmektedir. Ebay'in büyük veri konusunda yatırım yapmasına ve büyük veriyi büyümenin odağına koymasına yukarıdaki bu sorular neden olmuştur. Bize basit gelen bu sorunun arkasında beş milyar sayfa görüntüleme işlemi bulunduğunu ifade etmekte fayda var.
Ebay'in 2002 yılında kurduğu ve 13 terabayt olan ilişkisel veri tabanı sistemi bugün on dört petabayt boyutlarına ulaşmış, yüzbinlerce fiziksel donanım sistemi üzerinde çalışmaya başlamış ve her geçen gün ciddi oranda büyümeye devam etmektedir.
Netflix de benzer bir soru ile büyük veriyi kullanmaya başlamıştır; "Müşterim hangi filmleri izlemekten hoşlanır?" Bu sorunun cevabını bulabilmek için binlerce kişiden oluşan bir ekip hizmet vermektedir. Bu ekipte çalışan elemanlar, kişiselleştirme analizi, mesajlaşma analizi, içerik iletme analizi, cihaz analizi gibi pek çok konuda uzmanlar.
Netflix bu sorunun cevabını bulabilmek için 2009 yılında Netflix Prize adlı bir yarışma düzenledi. Yarışmanın amacı, müşterilerin önceki puanlamalarına dayanarak, bir filme kaç puan vereceğini tahmin edecek en iyi algoritmayı oluşturmaktı. Kazanan gruba 1 milyon dolar ödül verildi. Algoritmalar sürekli yenilenip eklemeler yapılsa da, orada kullanılan prensipler hala tavsiye motorunun temel öğelerini meydana getiriyor.
Kurumların büyük veriyi yeni değerler üretmek için kullanırlar. Bunu yapabilmenin en önemli yolu ise tutarlı öngörüler ve isabetli tahminler yapabilmektir.
Büyük veri sadece özel işletmelerinin kârlılık hedeflerine ulaşmalarını sağlayan bir araç değildir. Devlet kurumları da büyük veriden sıklıkla yararlanmaktadırlar. Covid-19 ile mücadelede Çin'in büyük veriyi nasıl kullandığını daha önceki yazımızda anlatmıştık. Şimdi de New York şehrinde, kanalizasyon kanalları bakımında nasıl kullanıldığına bir göz atalım:
New York City'de her yıl birkaç yüz rögar, iç kısımları ateş aldığından için için yanmaya başlar. Ağırlığı neredeyse 136 kilogramı bulan pik demirden yapılma rögar kapakları bazen patlar, birkaç kat yukarı fırlar ve yere düşerler.
Şehre elektrik tedarik eden kamu hizmet kuruluşu Con Edison, her yıl rögarların düzenli kontrolünü ve bakımını yapar. Geçmişte, bu iş tamamen şansa bağlıydı, kontrol edilmesi planlanan bir rögarın, patlamaya hazır olan rögar olması umulurdu.
New York kanalizasyon kanalları sadece atıklar için değil aynı zamanda farklı amaçlar için kullanılan kablolama için de kullanılmaktadır. New York alt yapı kanallarında dünyanın çevresini üç buçuk kere sarmaya yetecek kadar, 151.246 kilometre yeraltı kablosu vardır. Yalnızca Manhattan'da 51.000 rögar ve servis kutusu bulunmaktadır.
Bu altyapının bir kısmı, şirkete adını veren Thomas Edison zamanından kalmadır. 20 kablodan biri 1930'dan önce döşenmişti. 1880'lerden beri kayıt tutulmuş olmasına rağmen, bunlar karmakarışık formlar halindeydi ve kesinlikle veri analizi için tutulmamışlardı. Bu veriler genellikle muhasebe bölümünden ya da hata raporu notlarını elle yazan acil durum sevk memurlarından geliyordu. Kısaca, çok dağınık ve karmaşık bir veri mevcuttu.
Bu sorunu çözebilmek için veri uzmanları hemen işe koyuldular: sadece bir örneklem değil verinin hepsinin kullanılması gerekiyordu, çünkü on binlerce rögardan herhangi biri saatli bomba olabilirdi.

Veri madencileri dağınık veriyi bir makinenin işleyebileceği gibi biçimlendirdikten sonra, büyük bir rögar felaketinin 106 kestiricisiyle işe başladı. Daha sonra bu listeyi bir avuç en güçlü sinyale sıkıştırdılar. Bronx'un enerji nakil hatları şebekesinin bir testinde, 2008'in ortalarına kadar gelen ellerindeki bütün veriyi analiz ettiler. Daha sonra bu veriyi 2009 için problem yerlerini tahmin etmekte kullandılar.
Sistem çok başarılı bir şekilde çalıştı; Listelerindeki rögarların en başında gelen yüzde 10, sonunda ciddi kazalar yaşanan rögarların koskoca yüzde 44'ünü içeriyordu. Patlayan rögarlar vakası, gerçek dünyanın, zor problemlerini çözmek için, verinin yeni kullanımlara nasıl tabi tutulduğunu vurguluyor. [7]
İnternet üzerinde yaptığım en basit işlem bile kişiliğimiz ile ilgili bıraktığımız bir ayak izidir. Ne kadar dikkatli olursak olalım ayak izlerimizi her yere bırakmaktayız. Google ya da herhangi bir arama motoru üzerinde yaptığımız aramalar bizim politik tercihlerimizden tutun, tüketim tercihlerimize, ruh halimize, eğitim ve kültür düzeyimize kadar pek çok konuda bilgi üretmektedir.
Kredi kartı ile yaptığımız alış verişler ürün, marka tercihlerinin yanı sıra, tüketim alışkanlıklarımıza kadar pek çok bilgiyi barındırmaktadır.
Akıllı telefon kullanmamız sayesinde, dinlediğimiz müzikten, seyrettiğimiz TV kanallarına, en çok ziyaret ettiğimiz internet sitelerine, GPS ve navigasyon bilgileri sayesinde hangi saatte nereye gittiğimize, günde kaç adım attığımıza, sağlık kuruluşlarının yolladığı analiz sonuçlarında sağlık durumumuza kadar her adımımız takip edilip, depolanmaktadır.
Bu telefonlardaki kameralardan mikrofonlara kadar kullandığımız her özellik yaşam tarzımız, inançlarımız, tutumlarımız, tüketim alışkanlıklarımız gibi bilgilerin oluşmasının aracıdır. Hepimizin başına gelmiştir; telefon kapalıyken yaptığımız sohbetlerde kullandığımız pek çok kelime, bazı şirketlerin kelime arama programlarına (keyword search) takılmakta ve birkaç dakika içinde ilgimizi çekebilecek ürünlerin reklamları telefonumuza, elektronik postalarımıza gelmekte ya da sosyal medya, arama motoru kullanımımızda karşımıza çıkartılmaktadır.
Büyük üretici firmaların, "360 Derece Tüketici Pazarlaması" diye adlandırdıkları sistemin motoru, her türlü koruyucu yasaya rağmen, perde arkasında bölüşülen verilerden oluşturulan programlardır.
İnternetin günlük hayatımızda kullanılmasıyla birlikte, kişisel verilerimizin isteğimiz dışında, farklı amaçlarla kullanılmaya başlanmıştır. Bu verilerin pazarlama ve özellikle de politik amaçlarla kullanımı tüm dünyada tepki almıştır. Birçok ülke, kişisel verilerin izinsiz ve kötü amaçla kullanımını engellemek için yasalar çıkarmışlardır.
Ancak geldiğimiz aşamadaki asıl tehlike kişisel verilerimizin izinsiz kullanımından çok algoritmaların yarattığı olasılıklarda kendini göstermektedir. Algoritmalar bir kişinin kalp krizi geçirme (ve sağlık sigortası için daha fazla ödeme), ipotek karşılığı uzun vadeli konut kredisini ödememe (ve kredi alamama) ya da bir suç işleme (ve belki önceden tutuklanma) olasılığını tahmin edecektir.
Minority Report (Azınlık Raporu) isimli filmin açılış sahnesinde, büyük veriyi kullanarak tahminlerde bulunup, suç işleme eğilimi olan insanları proaktif davranarak tutuklayan polisler anlatılmaktadır.
Bu duruma benzer koşullar ABD'de gelişmeye başladı; tüm ABD eyaletlerinin yarısından fazlasındaki şartlı tahliye kurulları, bir kişiyi hapishaneden tahliye etmek ya da hapiste tutmak arasında karar verirken veri analizine dayanan tahminleri bir etken olarak kullanıyor.
Bu durum, veri diktatörlüğüne karşı özgür iradenin rolünün etik olarak göz önünde bulundurulmasına neden oluyor.
Bireyler hakkındaki büyük veri tahminlerinin aslında insanları eylemlerinden dolayı değil eğilimlerinden dolayı cezalandırmak için kullanılabilmesi rahatsız edicidir. Bu durum, özgür iradeyi yok sayar ve insanların haysiyetini zedeler. [8]

Ünlü yazar Yuval Noah Harari'nin 2018 yılında Davos'taki konuşmasında yaptığı tespitler son derece önemlidir. Gelecekle ilgili tehlikeyi algoritmaların yarattığı olasılıktan bir adım daha ileri götürüp, insan beyninin hack'lenmesine götürmektedir:
"Veriler neden bu kadar önemli? Bu soru önemlidir, çünkü sadece bilgisayarları değil, insanları ve diğer organizmaları da hack'leyebileceğimiz noktaya ulaşırız. Bu günlerde bilgisayarları ve e-posta hesaplarını, banka hesaplarını ve cep telefonlarını hack'lemek hakkında çok fazla konuşma var ama aslında büyük veri aracılığı ile insanları hack'leyebilme olasılığı artıyor. Şimdi bir insanı hack'lemek için basit olarak iki şeye ihtiyacınız var. Çok fazla bilgi işlem gücüne ve özellikle temelde biyometrik veri olmak kaydı ile çok veriye ihtiyacınız var. Ne satın aldığım veya nereye gittiğimle ilgili veri değil. Ama bedenimin içinde ve beynimin içinde neler olduğuna dair veriler. Bugüne kadar henüz hiç kimse insanları hack'lemek için gerekli bilgiişlem gücüne ve yeterli veriye sahip erişemedi."[9] Ancak bu hiç bir zaman da erişemiyeceği anlamına gelmiyor.
Harari, önümüzdeki 200 yıl içinde, büyük veriye sahip olanların beyinleri de hack'leyebileceğini öngörmektedir. Büyük veriye kimler sahip olacak, sorusuna ise devletler değil, büyük şirketlerin ya da dünyayı yöneten büyük ailelerin sahip olabileceğini iddia etmektedir.
Harari'ye göre şu an yaşayan insanlar özgür düşünebilen, kendi başına karar verebilen son nesildir. Beyinleri hack'lenen gelecek nesiller, kendilerine empoze edilen şekilde yaşayacaklar ama aldıkları kararları kendi özgür iradeleri ile aldıklarını zannedecekler.
Ben bir gelecek bilimci (futurologist) değilim, Harari'nin analizlerine elbette saygı duyuyorum. Ben de geleceğimizi belirleyecek en önemli gücün büyük veri olduğuna inanıyorum. Geleceğimizi büyük veriye sahip olacak güçlerin belirleyeceğine inanıyorum.
Fransız siyaset bilimci Maurice Duverger, azgelişmiş ülkelerde demokrasinin gelişemeyeceğini, diktatörlüklerin kaçınılmaz olduğunu söyler. Şanslı toplumlar daha hoşgörülü ve ilerici diktatörlerle, şansız toplumlar ise kötü ve gaddar diktatörle yönetilir.
Gelecekle ilgili de böyle düşünüyorum. Şayet şansımız yaver giderse büyük veri "iyilerin" eline geçer. Bu durumda mükemmel bir geleceğimiz olur. Ama tam tersi olur ve "kötülerin" eline geçerse de, öbür dünyadaki cehennemi bu dünyada yaşarız.
[1] MAYER-SCHÖNBERGER Viktor, CUKIER Kenneth, Büyük Veri Yaşama, Çalışma ve Düşünme Şeklimizi Dönüştürecek Bir Devrim, Paloma Yayınevi, İstanbul, Mayıs 2013. s.22
[2] ÖZDOĞAN Ogan, Büyük Veri Denizi, Elma Yayınevi, Ankara, Temmuz 2016. S.12
[3] MAYER-SCHÖNBERGER Viktor, CUKIER Kenneth. A.g.e. s.90-91
[4] BARNARD Marr, Büyük Veri İş Başında 45 Yıldız Şirket Büyük Veri'yi Nasıl Kullandı?. Kapital Medya, İstanbul 2016. s. 12
[5] ÖZDOĞAN Ogan, a.g.e., s.23
[6] ÖZDOĞAN Ogan, a.g.e. s.17
[7] MAYER-SCHÖNBERGER Viktor, CUKIER Kenneth. A.g.e. s.75
[8] MAYER-SCHÖNBERGER Viktor, CUKIER Kenneth. A.g.e. s.177
Kontrolsüz olarak geliştirilecek olan süper yapay zekâ uygulamalarının, değişik ölçeklerde, insanlığa zarar verme olasılığı elbette vardır. Bu yüzden, küresel ölçekte yasal düzenlemeler yapılmalıdır. Ama bu tehlikeye bakarak yapay zekânın insanlığa sağlayacağı faydaları da görmezden gelemeyiz
1920 Olimpiyat Oyunları, 20 Nisan - 12 Eylül 1920 tarihleri arasında Belçika'nın Antwerp şehrinde yapıldı. Bu oyunlar, I. Dünya Savaşı'ndan sonra düzenlenen ilk Olimpiyat Oyunlarıydı
Osmanlı Devleti'ni temsilen ilk kez 1906 Atina Ara Olimpiyatları'na İzmir'den ve Selanik'ten üç futbol takımı katılmıştı. Bu organizasyon, IOC tarafından Olimpiyat Oyunları olarak kabul edilmediği için, Osmanlı Devleti'nin katıldığı ilk Olimpiyat oyunları 1912 Stokholm oyunlarıdır

© Tüm hakları saklıdır.