
Yıllar içinde İnce Memedler'deki üslup değişiminin 20. yüzyıl Türk edebiyatındaki ya da Türkçedeki değişimle ilişkisi var mı? Bu ilişki veri madenciliği ile gösterilebilir mi?
Bu yazı İnce Memed roman dizisini veri madenciliği yöntemleri ile inceleyen üçlemenin ikinci bölümüdür. Üçlemenin "İnce Memedler'e Veri Madenciliğiyle Bakmak" adlı ilk bölümünde Yaşar Kemal’in 4 ciltten oluşan İnce Memed romanlarından (İM 1, İM 2, İM 3, İM 4) ikincisinin yazıldığı zamana ve veri madenciliğinin edebiyat araştırmalarında nasıl yapıldığına değiniyorum. Bu bölümdeyse yayımı 32 yıllık bir zaman penceresinde (1955-1987) yer alan İnce Memed romanlarında yazı üslubunun değişimine ilişkin veri madenciliğiyle elde edilen gözlemleri [1, 2] paylaşıyorum. Takiben, 20. yüzyılda Türkçede kelimelerin uzaması ve kelime köklerinin kısalması şeklinde gerçekleşen nicel değişimlerin [3, 4] ne ifade ettiğine ve bu gözlemlerin zaman içinde benzer bir değişim sergileyen İnce Memedler’de nelere işaret ettiğine değiniyorum. Yazı dizisinin üçüncü ve son bölümündeyse, veri madenciliği ile bulunanların edebiyat araştırmacıları için ne ifade edebileceğini ve dilin zaman içindeki değişimiyle ilgili birtakım tartışmaları okuyucunun dikkatine sunuyorum.
Bilgisayar bilimleri ve teknolojilerindeki ilerlemeye eşlik eden büyük veri imkânlarıyla birlikte günümüzde geniş yaygınlık kazanan veri madenciliği uygulamaları bir veri topluluğu içindeki açıkça görünmeyen oluşumları ve ilişkileri bulmayı amaçlar. Elde edilen sonuçların doğruluğunu istatistiksel yöntemlerle değerlendirir. Bizim ilgilendiğimiz problem, veri madenciliği yöntemleriyle İnce Memed roman dizisinde zaman içinde oluşan değişimlerin nicel olarak gösterilmesidir.
Sonuçlarını vereceğim çalışmalarda [1, 2] romanların metinleri veri madenciliğine uygun sayı dizisi şeklinde olan yapılara dönüştürülmüştür. Bu amaçla her roman eşit sayıda sözcük içeren, blok olarak adlandırılan pasajlara bölünmüştür. (Yapılan değerlendirmelerde blok büyüklüğü 5.000 kelime olarak alınmıştır: Birinci blok incelenen romanın ilk 5.000 sözcüğünü içerir; ikinci blok bir sonraki 5.000’ini, vb.) Romanların bloklara bölünmesi romanlarla ilgili gözlemlerin artmasını, anlatımdaki ayrıntıların izlenmesini ve çıkarılan sonuçların güvenilirliğini yükseltir. Sayıca artan ölçümler elde edilen çıkarımların doğruluğunu değerlendirecek olan istatistiksel testlerin daha hassas olarak yapılmasını sağlar. Metinlerin bloklara bölünerek incelenmesi bir doktorun teşhis amacıyla hastasının ateşiyle ilgili yapılan ölçümlerin ortalama değeri (romanın tümü) yerine, her bir ölçüme (bloklara) ve gözlemlerin değişimine bakmasına benzetilebilir.
Blok metinleri öznitelik olarak adlandırılan özellikleriyle tanımlanmıştır. Öznitelik olarak bloklardaki her bir: 1) cümle uzunluğunun, 2) kelimelerdeki hece sayısının, 3) kelime uzunluklarının ve 4) farklı kelime uzunluklarının kaç kez geçtiği saptanmıştır. Bu 4 özniteliğe ek olarak, kategorik nitelikte olan, bloklardaki: 1) sık geçen kelimelerin her birinin, ve 2) kelime türlerinin her birinin (ad, sıfat vb.) geçiş sıklığı da öznitelik olarak incelemeye dâhil edilmiştir. En çok kullanılan kelimeler, dört cildin bütününde ve her bir cildin en sık geçen 50 kelimesinde ortak olan 33 sözcük olarak tanımlanmıştır. Açıklık kazandırmak amacıyla özniteliklerden 3. ve 4. kalemlerin ne anlama geldiğine “Yavaş yavaş geliyor” pasajını kullanarak bakalım. Bu metinde 5 harf uzunluğunda 2 kelime ve 7 harf uzunluğunda 1 kelime vardır. Pasajın kelimelerini, tekrara izin vermeden içeren sözlükteyse 5 ve 7 harf uzunluğunda olan 2 farklı kelime bulunmaktadır: yavaş, geliyor. Verilen metin örneği için “ortalama kelime uzunluğu” ve “ortalama farklı kelime uzunluğu” sırasıyla 5,66 (17/3) ve 6 (12/2) harftir.) Her blok için ve her öznitelik için, o özniteliğin farklı değerlerinin o blok içindeki geçiş sayıları vektör olarak adlandırılan bir sayı dizisi halinde elde edilmiştir. Örneğin elimizde 100 blok olsa, her bir öznitelik için 100 vektör üretilecek ve elimizde incelemek üzere toplam 600 vektör bulunacaktır.
Öznitelik vektörü kavramını somutlaştırmak için, hece sayılarıyla ilgili 1.000 kelime içeren bir blok için bir önceki yazıda verdiğim örneğe yeniden bakalım. Söz konusu blok için 1 ila 6 hece içeren kelimelerin sayılarına karşılık gelen sayı dizisi (vektör) şu şekilde verilmiştir: <188, 378, 270, 121, 36, 6>. Bu sayılar 188 kelimenin tek heceli, 378 kelimenin çift heceli ..., 6 kelimeninse 6 heceli olduğunu göstermektedir. Vektörde geçen sayıların toplamı (188 + 378 + ... + 6) 999 olduğuna göre, altıdan fazla hece içeren kelime sayısı binde birdir.
Roman dizisinin kelimeleriyle ve bloklarıyla ilgili sayılar sırasıyla Tablo 1 ve Tablo 2’de görülebilir. Tablolarda cümle uzunluğu kelime olarak verilmiştir. Tablo 2’de bloklardaki ortalama farklı kelime uzunluğu için verilen değer Tablo 1’de romanlar için verilen değerlerden küçüktür: Bunun nedeni birçok kısa kelimenin hemen her blokta, uzun kelimelerinse ancak bazı bloklarda yer almasıdır. Benzer durum Tablo 1’in son sütununda da görünmektedir. Blok uzunluğunun büyük olması sebebiyle (5.000 kelime) her iki tabloda da ortalama kelime uzunluğu hemen hemen (verilen hassasiyet içinde) aynıdır.
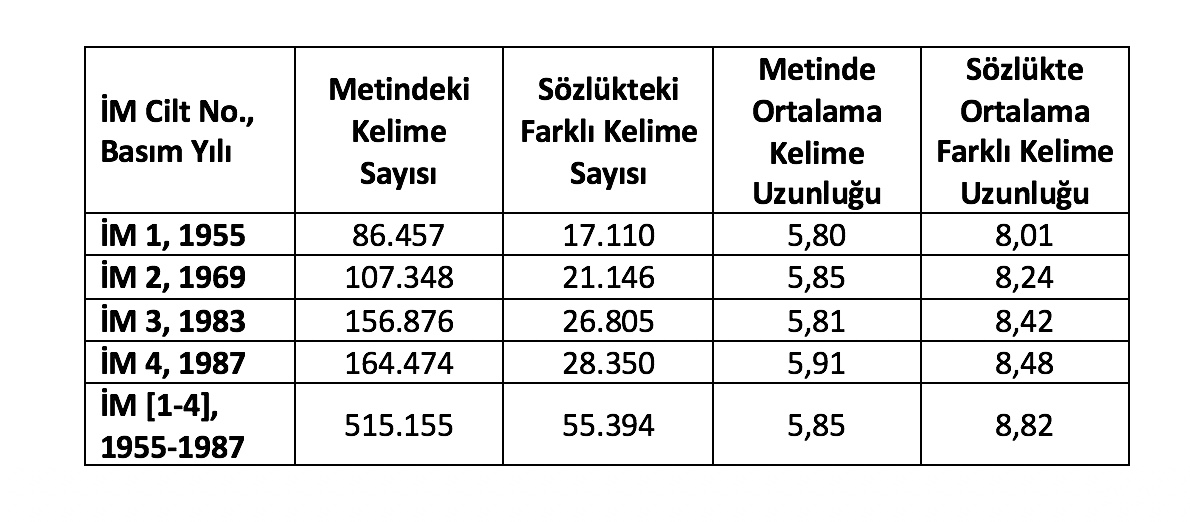 Tablo 1. İnce Memed dizisinin her bir romanının ve romanların toplam metninin kelimeleriyle ilgili sayılar.
Tablo 1. İnce Memed dizisinin her bir romanının ve romanların toplam metninin kelimeleriyle ilgili sayılar.
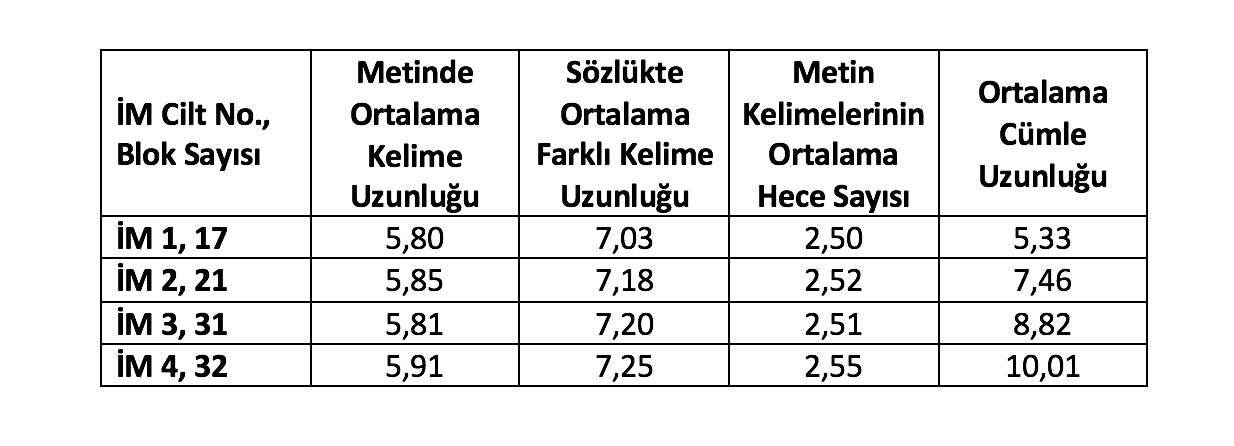 Tablo 2. İnce Memed dizisinde sayısal özniteliklerin 5.000 kelimelik bloklar için ortalama geçiş sayıları.
Tablo 2. İnce Memed dizisinde sayısal özniteliklerin 5.000 kelimelik bloklar için ortalama geçiş sayıları.
Tablo 2’de verilmiş olan, bloklar için elde edilen özniteliklerle ilgili ortalama değerler, İM 3 için gözlenen birkaç sapma dışında kelime uzunluğu, farklı kelime uzunluğu, kelime hece sayısı ve cümlelerin uzunluğu özniteliklerinin dizinin ilerleyen ciltlerinde artmakta olduğunu göstermektedir. Bu değişim özellikle cümle uzunluğu özniteliğinde belirgin olarak gözlenmektedir. MANOVA (multivariate analysis of variance) olarak adlandırılan istatistiksel test Tablo 2’deki her öznitelik için verilen ciltlere karşılık gelen ortalama değerlerde kayda değer fark olduğunu göstermektedir [1, 2]. Şimdi daha ayrıntılı olarak İnce Memed romanlarıyla ilgili üç farklı istatistiksel incelemenin sonuçlarına bakalım.
Romanların zaman içindeki değişimini sayısal olarak ölçmek amacıyla, kategorik olmayan özniteliklerle ilgili her bir blok için elde edilen gözlemler kullanılarak ANOVA (analysis of variance) olarak adlandırılan istatistiksel testler yapılmıştır. Bu deneylerde geçerliliği istatistiksel olarak gösterilmiş olan şu sonuçlar elde edilmiştir.
Cümle Uzunluğu: Ortalama cümle uzunluğu her ciltte kendinden önce gelen cilt(ler)den daha fazladır.
Hece Sayısı: Kelimelerdeki ortalama hece sayısı İM 4’te İM 1’e göre daha fazladır.
Kelime Uzunluğu: Kelimelerin İM 4’deki ortalama uzunluğu İM 1 ve İM 3 için elde edilen ortalamalardan daha fazladır.
Farklı Kelime Uzunluğu: Farklı kelimelerin İM 2, İM 3 ve İM 4’deki ortalama uzunluğu İM 1’deki ortalama uzunluğa göre daha fazladır.
Sonuçlar yukarıda belirtilen her özniteliğin zaman içinde istatistiksel anlamda kayda değer ölçülerde arttığını göstermektedir.
Roman dizisi bloklarının altı özniteliğin ayrı ayrı kullanımıyla yapılan çapraz doğrulamalı diskriminant analiziyle (cross-validated discriminant analysis) yapılan sınıflandırma sonuçları Tablo 3’te özetlenmiştir. (Çapraz doğrulama sırasında sınıflandırılacak blok dışında kalan bloklar kullanılarak her roman için tanımlayıcı profil üretilmekte ve sınıflandırılacak bloğun bu profillere olan benzerliği ile karar verilmektedir.) Bu tabloda yatay İM 1 sırasının dikey İM 1 sütunu ile kesiştiği, sayıların koyu renkte verildiği gri hücreler İM 1’e ait olan blokların kaçının çeşitli öznitelikler için doğru olarak sınıflandırıldığını göstermektedir. Benzer gözlemler gri renkte verilmiş olan İM 2, İM 3 ve İM 4’e ait olan öteki çapraz hücreler için de geçerlidir. İM 1’e ait olan 17 metin bloğundan 17’si de cümle uzunluğu özniteliği kullanılarak doğru olarak sınıflandırılmıştır. Hece sayısı özniteliği kullanılarak yapılan sınıflandırmaysa 17 bloktan 15’inin doğru sınıflandırılmasını sağlamıştır. Bu tablodaki çapraz hücreler (İM 1 - İM1) ... (İM 4 - İM 4) dışındaki hücreler ise yanlış sınıflandırma sayısını ifade etmektedir.
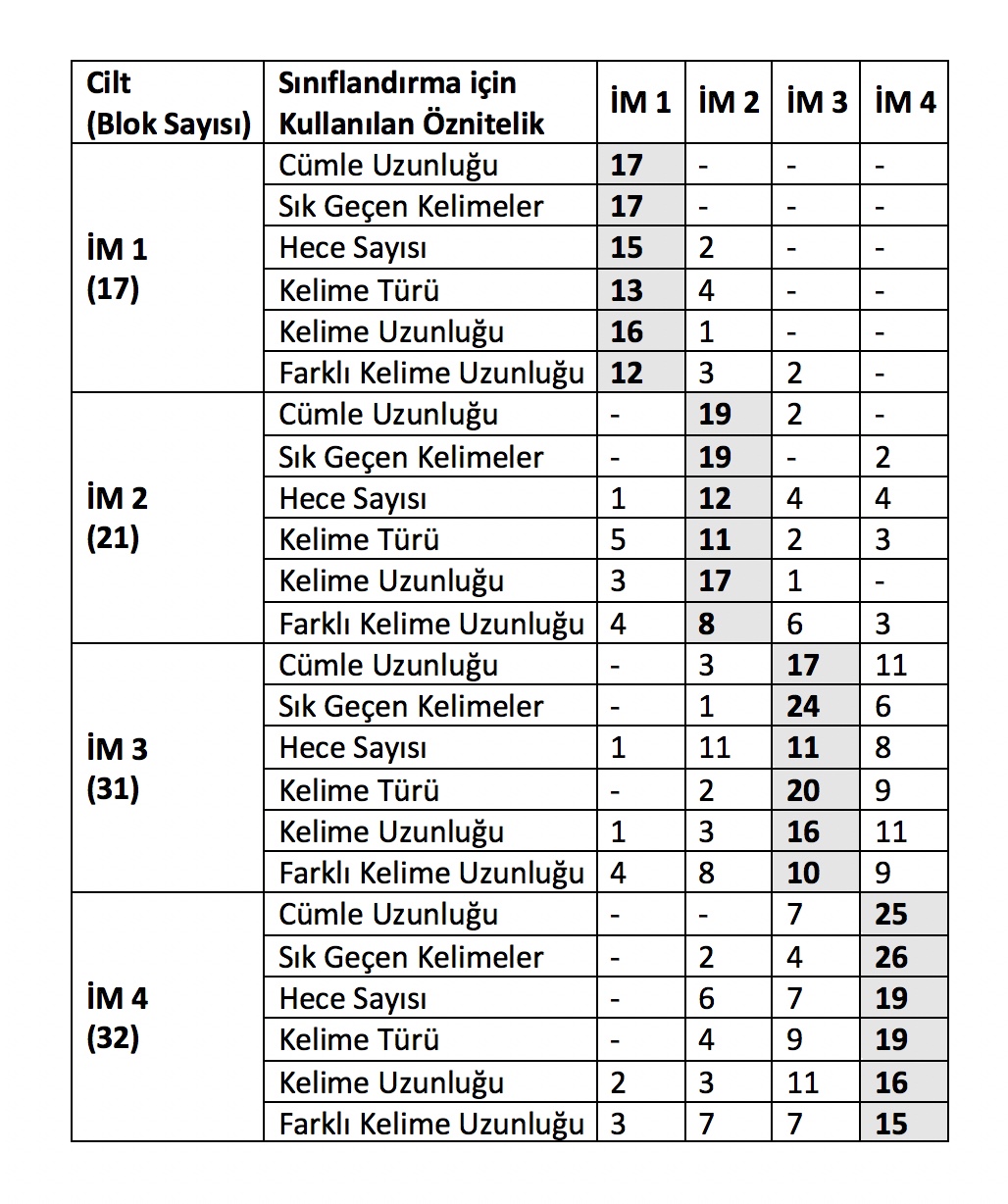
Tablo 3. İnce Memed dizisinin bloklarının çapraz doğrulamalı diskriminant analizi yöntemiyle sınıflandırılma sonuçları. Çapraz gri hücreler - (İM 1-İM 1), ... , (İM 4 - İM 4)- doğru, beyaz hücreler - (İM 1 - İM 2), ... , (İM 4 - İM 3)- yanlış sınıflandırılan blok sayılarını göstermektedir [2].
Öznitelikler blokların doğru sınıfa atanmasında farklı oranlarda başarılı olmaktadır. Ciltler arasındaki zaman aralığı arttıkça, romanlara ait olan blokları birbirlerinden ayırt etmede daha başarılı olunmuştur. “Sık geçen kelimeler özniteliği” ile, İM 4 cildinin toplam 32 bloğundan yanlış sınıflandırılan toplam 6 bloğun 4’ü İM 3, 2’si İM 2 bloğu olarak sınıflandırılmıştır. Benzer durumlar öteki ciltler ve öznitelikler için de gözlenmektedir. “Cümle uzunluğu özniteliği” ile ilgili sonuçlara bakacak olursak: İM 1’in bütün blokları doğru olarak sınıflandırılmıştır; aynı öznitelikle İM 3 ve İM 4’ün blokları birbirine kayabilmektedir: İM 2’ninse yine aynı öznitelikle sadece 2 bloğu yanlış ve İM 3 olarak sınıflandırılmıştır.
Roman dizisi bloklarını cümle uzunluklarına göre ayrıştıran temel bileşenler analiziyle (principal component analysis) elde edilen sonuçlar Şekil 1’de verilmiştir [1, Figure 4]. Şekilde soldan sağa doğru İM 1, İM 2, İM 3 ve İM 4’ün blokları sırasıyla eşkenar dörtgen, kare, üçgen ve çarpı işaretleriyle gösterilmiştir; x ve y eksenlerindeki sayılar (Prin1, Prin2) çok boyutlu cümle uzunlukları vektörlerinin iki boyuta yansıtılmış özetidir. İki nokta arasındaki mesafe, karşılık gelen iki blok arasındaki benzerliği ifade etmektedir. Şekil İM 1’e ait olan eşkenar dörtgenle gösterilen blokların öteki roman bloklarından tamamıyla farklı olduğunu göstermektedir. İM 2, İM 3 ve İM 4’ten farklıdır, ancak bazı blokları her ikisiyle de örtüşebilmektedir. İM 3 ve İM 4 arasındaysa göze çarpıcı bir örtüşme gözlenmektedir: Bu durum yazarın son iki cildi önce üç roman olarak planlayıp sonra birleştirerek ikiye bölmesiyle koşutluk göstermektedir. [5, s. 183]
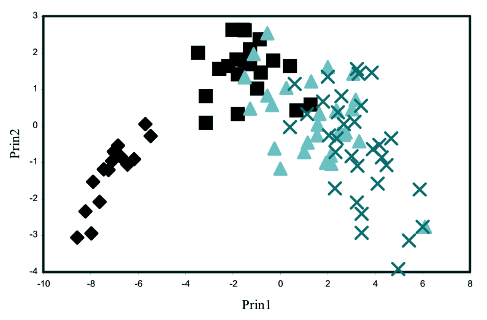
Şekil 1. İnce Memed dizisinin bloklarının cümle uzunluğu özniteliği kullanılarak temel bileşenler analizine göre dağılımı. Simgeler ♦: İM 1, : İM 2, ▲: İM 3, x: İM 4 bloklarını göstermektedir.
İnce Memedler’de yıllar içinde gözlenen değişimi gördükten sonra, 1) “Bu gözlemlerin 20. yüzyıl Türk edebiyatındaki olası bir değişimle”, 2) “Türkçede olan değişimle ilişkisi var mı?” soruları akla gelmektedir. Şimdi de bu iki sorunun yanıtlarına bakalım.
Birinci soruyu yanıtlamak için 20. yüzyıl Türk edebiyatında kelime kullanımındaki olası değişikliği ölçmeye yönelik olan, her çeyrek yüzyıldan 10 roman alarak toplam 40 romanın metninin tamamını kullanan çalışmanın sonuçlarına bakalım. [3]
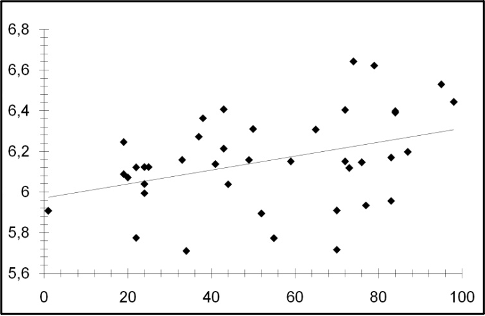
Şekil 2. 20. yüzyıl Türk edebiyatından 40 romanın metinlerindeki ortalama kelime boylarına göre zaman içindeki dağılımı: x ve y eksenleri sırasıyla romanların 1900’lerdeki basım yılını ve ortalama kelime uzunluğunu göstermektedir. Ortalama Kelime Uzunluğu (Yıl) = 5,9741 + 0,00368 x (Yıl - 1900) [3]
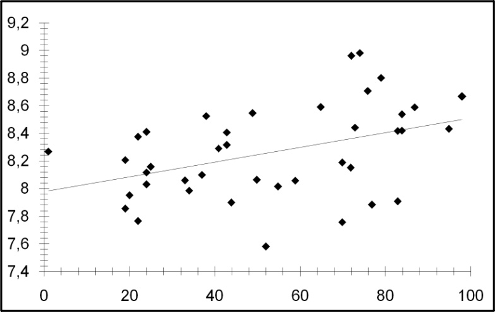
Şekil 3. 20. yüzyıl Türk edebiyatından 40 romanın sözlüklerindeki ortalama farklı kelime boylarına göre zaman içindeki dağılımı: x ve y eksenleri sırasıyla romanların 1900’lerdeki basım yılını ve ortalama farklı kelime uzunluğunu göstermektedir. Ortalama Farklı Kelime Uzunluğu (Yıl) = 8,0127 + 0,00609 x (Yıl - 1900) [3]
Söz konusu çalışma yüzyıl içinde kelimelerin roman metninde ve roman sözlüklerinde uzadığını göstermektedir. Romanlardaki (metinde) ortalama kelime ve (sözlükte) farklı kelime uzunluklarının zaman içindeki değişimi sırasıyla Şekil 2 ve Şekil 3’te verilmiştir. Şekillerde görülen her bir eşkenar dörtgen farklı bir romana karşılık gelmektedir. Araştırmada kullanılan romanlardan birincisi 1901’de yayımlanan Mehmet Rauf’un Eylül, sonuncusuysa Ahmet Altan’ın 1998’de yayımlanan Kılıç Yarası Gibi adlı romanıdır. Bu romanların metinlerindeki ortalama kelime uzunluğu sırasıyla 5,906 ve 6,447 (harf) olarak gözlenmiştir. Bu iki romanın sözlüklerindeki ortalama farklı kelime uzunluğu sırasıyla 8,264 ve 8,668 olarak ölçülmüştür. Gözlemler zaman içinde kelimelerin uzadığını göstermektedir.
Şekil 2 ve 3’te zaman ilerledikçe yukarıya doğru yükselen düz çizgiler, 20. yüzyıl Türk edebiyatında metinlerde geçen kelimelerin ve metinlerde bulunan farklı kelimelerin ortalama uzunluğunun yıllar içindeki değişimini yaklaşık olarak göstermektedir. Şekillerin alt başlığında ağırlıklı en küçük kare regresyonu (weighted least square regression) yöntemiyle elde edilen kelime uzunluklarının zaman içindeki değişimiyle ilgili denklemler verilmiştir. Bu denklemler 20. yüzyılın herhangi bir yılında Türk edebiyatında yayımlanmış, rastgele bir romandaki ortalama kelime ve farklı kelime uzunluğunun harf sayısı olarak tahmini değerini vermektedir. Kısaca, denklemler yazarların kelime seçimleriyle dilin yıllar içindeki değişimi arasındaki bağlantıyı göstermektedir. Şekil 2’nin altında verilen denklem kullanılarak 1955 yılında basılan İM 1 için ortalama kelime uzunluğu harf sayısı olarak şu şekilde hesaplanır: Ortalama Kelime Uzunluğu (1955) = 5,9741 + 0,00368 x (1955 - 1900) = 6,1765. Tablo 1’de İM 1 için gerçek ortalama kelime uzunluğu 5,80 harf olarak verilmiştir; bu sayı denklem kullanılarak bulunan sonuçtan daha küçüktür. Bu durum denklemin çıkartımı yapılırken ortaya çıkan yanılma payıyla açıklanabilir.
Her iki şekil de kelime boylarının uzamasının kaçınılmaz olduğunu sergilemektedir. Bu denklemlerin başka bir yorumu da şöyledir: Yazarların kelime seçimleri dili etkilemekte ve kelimeler uzamaktadır. Dil de zaman ilerledikçe daha uzun kelime kullanımını yazarlar için âdeta zorunlu hale getirmektedir. İnce Memed dizisinde de metin içindeki kelimeler ve farklı kelimeler, Tablo 1’de ve roman dizisiyle ilgili olarak yapılan yukarıda verilen ANOVA deneyleriyle de gösterildiği üzere, zaman içinde kayda değer biçimde uzamaktadır: Gözlemler roman dizisinde izlenen kelime uzayışının Türk edebiyatındaki durumun bir yansıması olduğunu gösteren niteliktedir.
Türkçede yıllar içinde değişim olduğunu biliyoruz. Yukarıdaki soruyu yanıtlamak için Türkçedeki değişimi somut olarak saptamayı amaçlayan bir araştırmanın [4] sonuçlarına kısaca bakalım. Yabancı dillerdeki yedi edebi eserin yaklaşık elli yıl arayla Türkçeye yapılan çevirilerini kullanan bu çalışma dilin değişimi konusunda çeşitli gözlemler sağlamaktadır. Örneğin Shakespeare’in Macbeth adlı eserinin Orhan Burian’ın 1946 yılında yaptığı çeviri ve aynı çevirinin 1999 yılında yayıncı tarafından sadeleştirilmiş sürümü için elde edilen sonuçlar şöyledir: Birinci metin 14.744, ikincisi 14.342 kelime içermektedir. Yayın yılları 1946/1999 için sırasıyla (ortalama değerler olarak) kelime uzunluğu: 5,84/5,91, kelime kök uzunluğu: 3,95/3,88, kelime ek uzunluğu: 1,89/2,03 harf olarak gözlenmiştir. Metin içinde geçen her 100 kelime yaklaşık olarak 1946 yılında 14, 1999 yılındaysa 12 farklı kökten üretilmiştir. Kelime başına düşen kök sayısının zaman içinde azalması Türkçede kelime dağarcığının eskiden yeniye geçişte daraldığını göstermektedir. Eski ve yeni çevirilerin kelime sayısında istatistiksel anlamda kayda değer bir fark olmaması, kelime boylarının uzamış kök boylarınınsa kısalmış olması, çağdaş Türkçede dilin ifade gücünü eski ile aynı düzeyde tutmak için, daha az sayıda olan kök sayısının telafisi amacıyla daha fazla ek kullanıldığını göstermektedir. [4]
Çevirilerde yıllar içinde gözlenen kelimelerin uzaması İnce Memedler’de de gözlenmektedir. Çevirilerde kelimelerdeki ek uzunluğunun harf olarak artışının benzeri, İnce Memed roman dizisinde kelimelerin hece sayısının artışı şeklinde gerçekleşmektedir. Peki, çevirilerde gözlenen kelime üretiminde, kök boyunun kısalmasının da işaret ettiği kelime üretiminde azalan sayıda farklı kök kullanılması, sonuçta kelime dağarcığının daralması İnce Memed dizisinde de var mıdır? Bu sorunun tahmini cevabı, çevirilerin ve roman dizisinin kelimeleriyle ilgili gözlemlerin benzerliğinden ötürü “evet” olacaktır; asıl cevabıysa çeviriler yardımıyla yapılan çalışmayı andıran yeni araştırmalar verecektir. Yazı dizisinin üçüncü ve son bölümünde yukarıda verdiğim gözlemlerin düşündürdüklerine değineceğim.
•
KAYNAKLAR
[1] Patton, Jon M. ve Fazlı Can, “A Detailed Stylometric Investigation of the İnce Memed Tetralogy”,Technical Report #MiamiU-CSA-04-001, Miami University, Oxford, OH, 2004.
http://www.cs.bilkent.edu.tr/%7Ecanf/publications/imstyle122504.pdf. Son erişim tarihi: 20.12.2020.
[2] Patton, Jon M. ve Fazlı Can, “A Stylometric Analysis of Yaşar Kemal’s İnce Memed Tetralogy”, Computers and the Humanities, 2004, 38(4): 457-467.
[3] Can, Fazlı ve Jon M. Patton, “Change of Word Characteristics in 20th Century Turkish Literature: A Statistical Analysis”, Journal of Quantitative Linguistics, 2010, 17(3): 67-90.
[4] Altıntaş, Kemal, Fazlı Can ve Jon M. Patton, “Language Change Quantification Using Time-Separated Parallel Translations”, Literary & Linguistic Computing, 2007, 22(4): 375-393.
[5] Çiftlikçi, Ramazan, Yaşar Kemal: Yazar, Eser, Üslup, Ankara, Kültür Bakanlığı Yayınları, 1997.

